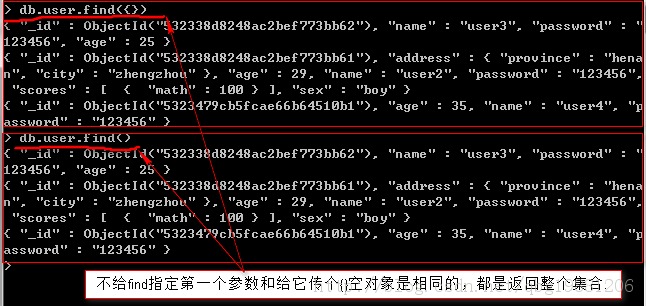
GridFS简介
mongoDB的文档以BSON格式存储,支持二进制的数据类型,当我们把二进制格式的数据直接保存到mongoDB的文档中。但是当文件太大时,例如图片和视频等文件,每个文档的长度是有限的,于是mongoDb会提供了一种处理大文件的规范--GridFS。
GridFS实现原理
在GridFS数据库中,默认使用fs.chunks 和fs.files来存储文件,其中fs.files集合存放文件的信息,fs.chunks存放文件的数据,一个fs.files集合中的一条记录内容如下,即一个file信息如下所示:
复制代码 代码如下:
{
"_id" : ObjectId("4f4608844f9b855c6c35e298"), //唯一id,可以是用户自定义的类型
"filename" : "CPU.txt", //文件名
"length" : 778, //文件长度
"chunkSize" : 262144, //chunk的大小
"uploadDate" : ISODate("2012-02-23T09:36:04.593Z"), //上传时间
"md5" : "e2c789b036cfb3b848ae39a24e795ca6", //文件的md5值
"contentType" : "text/plain" //文件的MIME类型
"meta" : null //文件的其它信息,默认是没有”meta”这个key,用户可以自己定义为任意BSON对象
}
对应fs.chunks中的chunk(中文意思数据块),如下所示:
复制代码 代码如下:
{
"_id" : ObjectId("4f4608844f9b855c6c35e299"), //chunk的id
"files_id" : ObjectId("4f4608844f9b855c6c35e298"), //文件的id,对应fs.files中的对象,相当于fs.files集合的外键
"n" : 0, //文件的第几个chunk块,如果文件大于chunksize的话,会被分割成多个chunk块
"data" : BinData(0,"QGV...") //文件的二进制数据,这里省略了具体内容
}
默认大小是256k,所以把文件存入到GridFS过程中,如果文件大于chunksize,则把文件分割多个chunk,再把这些chunk保存在fs.chunks中,最后再把文件信息存入fs.files中。
在读取文件的时候,先根据查询的条件,在fs.files中找到一个合适的记录,得到“_id”的值,再根据这个值到fs.funks中查找所有files_id 为 _id 的chunk,并按照“n”排序,最后依次读取chunk中的“data”对象的内容,还原成原来的文件。
注:
1、GridFS不自动处理md5相同的文件,对于md5相同的文件,如果想在GridFS中只有一个存储,要用户处理,md5值的计算由客户端完成。
2、因为GridFS在上传文件过程中是先把文件数据保存到fs.chunks,最后再把文件的信息保存到fs.files中,所以如果上传文件过程中失败,有可能在fs.chunks中出现垃圾数据,这些垃圾数据,可以定期清理掉。
版权声明
本文仅代表作者观点,不代表本站立场。
本文系作者授权发表,未经许可,不得转载。
本文地址:/shujuku/MongoDB/105229.html